Kubernetes Cronjob 101: part 2
In the first part we focused on how to set up your first cronjob with the proper configuration and manipulate them with the Kubernetes cli. In this second part, we will give you a more detailed explanation of our workflow
The need
One issue we faced with our initial workflow was that not all of our jobs could be run concurrently, so when we were working on separate branches, we would create a lock on stateful resource such as a database.
The solution
The solution we came up with, relies on using the --from option when creating a job that expects a deployed cronjob
kubectl create job --from=cronjob/<cronjob_name> job_name
So when we start working on a new cronjob, our workflow is as follows:
- Create a suspended cronjob
- Check cronjob deployment
- Create a job from this cronjob with --from and check out the result
- Goto 1 until it work as expected
- Deploy it in production
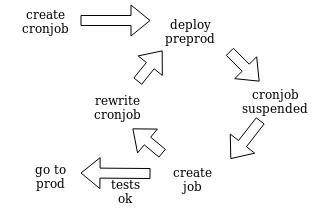
This help avoids the issue of manually changing schedules after each deployment to start the jobs, or letting bugged job stack up, possibly locking down resources.
One shot job from recurring cronjob
The limitation when creating job this way is that you can’t alter it.
Therefore, what will you do if you have to handle occasional operations such as catching up for ETL job or rerun failed job with increased limits (timeout, CPU, …) ?
For example, let’s say you have a cronjob that runs every day and uses “yesterday” as starting date by default. What we do is rely on command line parameters for the script and let it set a default value for which there is no input. This way we can manually edit the cronjob:
#normal run that load yesterday data
command: ["etl_script"]
args: ["--bucket-name", "name"]
#catchup run that load specific date
command: ["etl_script"]
args: ["--bucket-name", "name", "--start-date", "2018-02-1", "--end-date", "2018-03-01"]
Now that you have this code in production if you want to rerun it using previous dates, what you can do is create a duplicate of the cronjob.
kubectl get cronjob <cronjob-name> -o json > /tmp/<cronjob-name>.json && sed -i 's/<cronjob-name>/<cronjob-name>-duplicate/' /tmp/<cronjob-name>.json && kubectl create -f /tmp/<cronjob-name>.json
Edit its content to reflect your new limitations (CPU, RAM, deadline) and then create a job from your duplicated cronjob (I recommend setting “suspend” to initially true to avoid concurrent runs ;) ) without impacting the one handling the normal run.
Interpolation in cronjob generation
As we said, you need to rely on a script to handle the setup of a default value because you can’t call Linux command in you args, like date for example.
But did you know that you can use variable sets in env and envFrom in your script? You just need to call them using $() instead of $. It can be useful if you don’t want your script to rely on system env variables
command: ["script"]
args: ["--aws-secret-access-key=$(AWS_SECRET_ACCESS_KEY_USER)", "--aws-access-key-id=$(AWS_ACCESS_KEY_ID_USER)", "--aws-region=$(AWS_DEFAULT_REGION)",
"--postgres=$(POSTGRES_URI)","--s3-bucket=$(AWS_TRACKING_BUCKET)"
envFrom:
- secretRef:
name: {{ .Values.secrets_postgres_database }}
- configMapRef:
name: {{ .Values.config_aws }}
Logging with lifecycle
It’s really convenient to be able to raise an alert when a job fails, sadly as we saw in the previous article this is not always easy due to the job itself, so what we do now is to generate a log at the start and the end on the pod runtime using the lifecycle option in our cronjob definition
kind: CronJob
metadata:
name: example
spec:
schedule: "10 3,15,20 * * *"
concurrencyPolicy: "Forbid"
suspend: false
jobTemplate:
spec:
template:
metadata:
annotations:
log/format: json
spec:
containers:
- name: example
image: python
lifecycle:
postStart:
exec:
command: ["/bin/sh", "-c", "echo Container for load pipeline started"]
preStop:
exec:
command: ["/bin/sh","-c","echo Container for load pipeline stopping"]
imagePullPolicy: Always
command: ["script.py"]
args: ["--flag","value"]
env:
- name: NAME_OF_VARIABLE_IN_JOB
valueFrom:
configMapKeyRef:
name: configmap_name
key: key_in_configmap
resources:
requests:
memory: "4Gi"
cpu: "1"
limits:
memory: "8Gi"
cpu: "2"
restartPolicy: Never
But keep in mind that if you use a docker container with an entrypoint you can run into some issue where the lifecycle will be executed AFTER the entrypoint.
EDIT:
Just found this great article on how to raise an alert if you use prometheus/grafana to analyze your Kubernetes cluster, here
Ordering containers
Another great feature of Kubernetes is the init containers option, it consists of a list of ordered containers that will be run sequentially.
Each container waiting for the previous one to finish before launching, this is mainly used with the service API to sync them when deploying.
But this also works with a cronjob, so we can use them to do some sync or clean up before starting a job.
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: example
namespace: default
spec:
schedule: '*/1 * * * *'
jobTemplate:
spec:
template:
spec:
initContainers:
- name: wait-for-service
image: busybox
command: ['sh', '-c', 'until nslookup myservice; do echo waiting for myservice; sleep 2; done']
- name: wait-for-db
image: postgres
command: ['pg_isready', '-h', 'someremotehost']
- name: clean-up-db
image: busybox
command: ['sh', '-c', 'psql -f clean_up.psql']
containers:
- name: fake-job
image: own-image
command: ['sh', '-c', 'echo The app is running! && sleep 3600']
restartPolicy: OnFailure
Conclusion
Time to wrap things up and go
So, in conclusion, even if the cronjob API itself didn’t evolve much since part 1, there are many ways to improve your current use by looking at other tools in Kubernetes whether it is kubectl, the API options or even by integrating it to your own CI.