Python Packaging : How we manage it at JobTeaser
How we managed to host own repository for python packaging on AWS
The need
Here at JobTeaser, we found ourselves duplicating a great amount of code between text cleaning operations for machine learning projects, AWS wrapper, and Kafka helper.
The solution we found to this trouble was to extract our reusable code into proper packages (correctly tested and documented), before pushing it to our own package server.
Previous solution
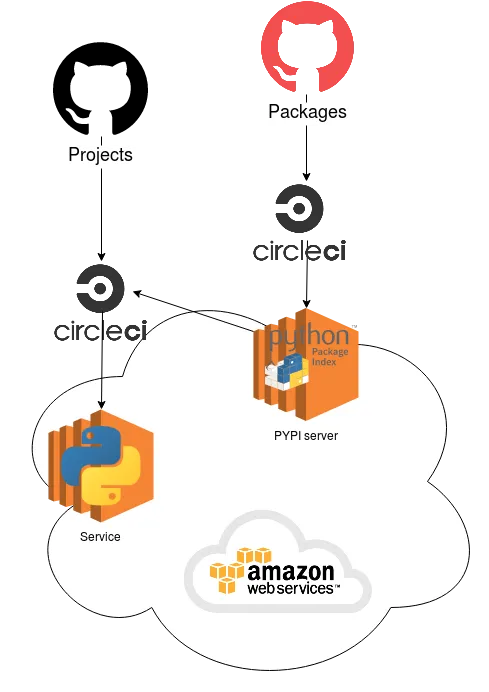
The previous solution with own pypi
The current solution relies on an EC2 machine that contains a pypi server. The CI (here CircleCi) will build→test →push a new version of the package to the pypi server.
Once published, other projects can use the package in their CI process by requesting it from pypi server.
Previous solution limitations
- Can’t have default read-only for everyone and an authenticated user at the same time.
- Needs fine access control at user level because CircleCI doesn’t have fixed IPs.
- Sometimes the pypi server hangs for no reason and we have to restart it.
- All the data is stored on the server without any backup!
Looking for alternative(s)
Because our infra already runs on AWS, this search was limited to solutions that used S3 as a backend, after some time we found two solutions:
S3pypi
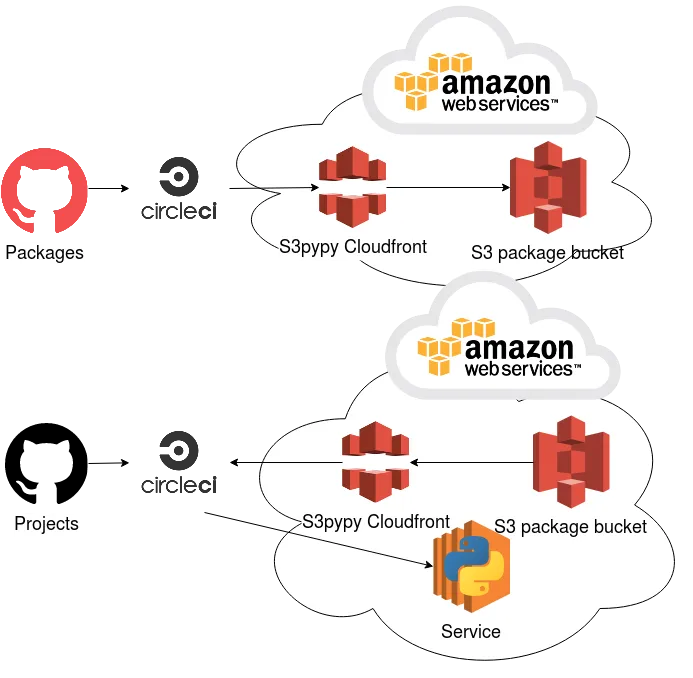
As you can see the strongest point of the S3pypi solution is that it is straightforward.
It effectively uses a Cloudfront to expose s3 content in the same way that a static website.
But at Jobteaser, we manage all our AWS resource using Terraform. So we would have to take their templating and adapt it, not to mention that the security relies only on the Cloudfront setup.
Pros:
- Full AWS
- Low costs
Cons:
- Setup doesn’t integrate easily with our tooling (Terraform)
- Doesn’t rely on user level access control
Pypicloud
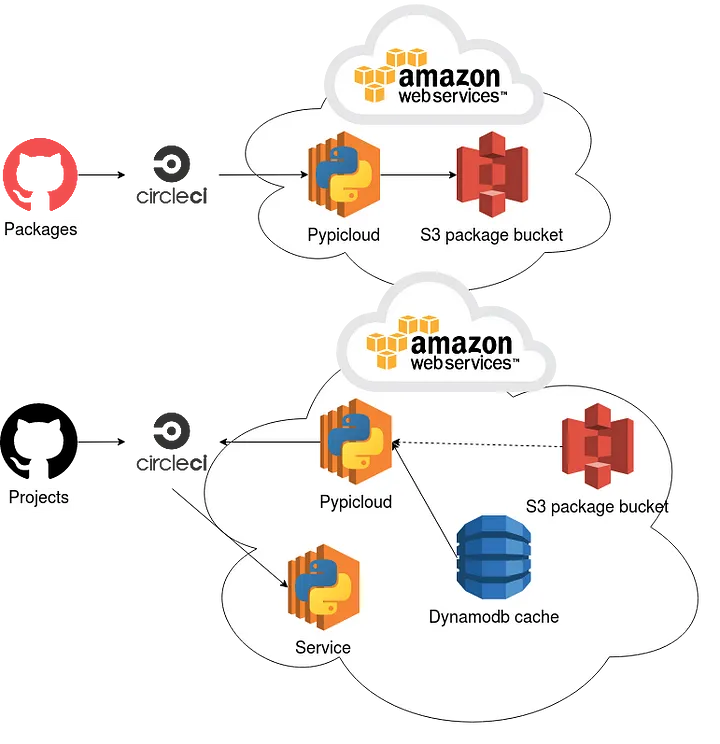
On the other hand we have Pypicloud that goes in the opposite direction with a more complex and modular solution.
Similarly to the current pypi solution, it requires a dedicated server but also has the added need for external storage and a caching service. But on the bright side, you can actually use any option you want for these components.
Pros:
- Modular solution
- Has users and more configuration than pypi
- Nice GUI for admin
Cons:
- Needs a more complex setup
- Costs are slightly higher
- Users need to be created from the admin interface
In the end the winner was Pypicloud, because, for the deployment, Cloudfront’s hidden complexity and the need to rely only on AWS IAM were unacceptable.
Implementing the new solution
First, we need to create an s3 bucket, with access rights granted to a unique AWS user, in our case, the Pypicloud server.
One major change from the recommended AWS configuration is the use of a PostgreSQL RDS as a cache instead of Dynamodb.
We made this choice because for internal use the added complexity and cost were not worth it.
Here’s anexample of configuration (only containing cache and backend conf):
[app:main]
use = egg:pypicloud
pypi.storage = s3
storage.region_name = eu-west-1
storage.bucket = <placeholder>
storage.prefix = packages/
storage.redirect_urls = true
pypi.auth = sql
db.url = <placeholder>
auth.db.url = <placeholder>
pypi.default_read =
everyone
pypi.default_write =
authenticated
Integration in the current pipeline
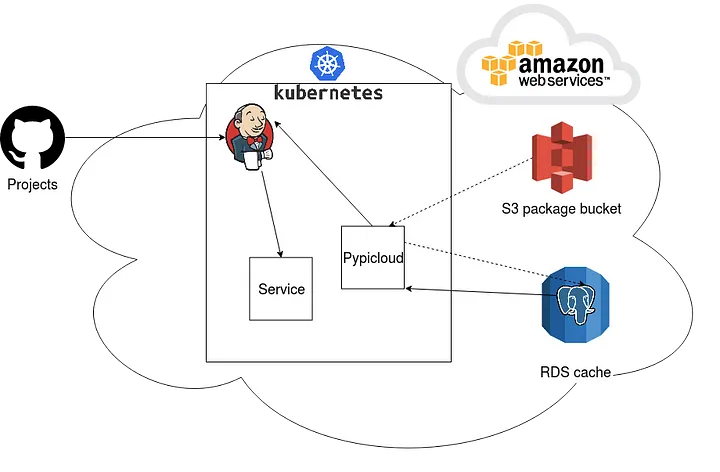
In the meantime, we’ve actually migrated on Kubernetes, with a CI on Jenkins.
So here is the package publishing pipeline:
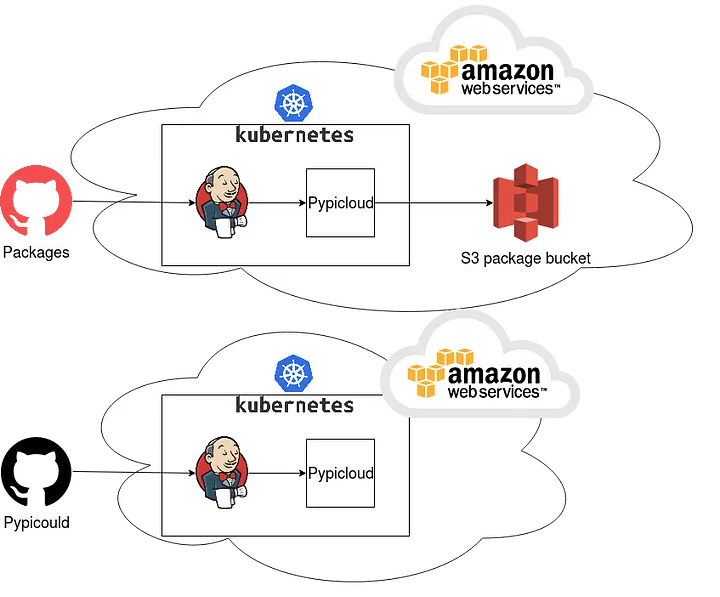
For the package publication, we have a Github repository that contains Pypicloud configuration, a Dockerfile and Kubernetes resources for the server container that will be deployed.
This repository also contains other packages projects that will be tested in the CI before being built and published using a dedicated user, as we saw before this published package will be sent to Pypicloud to be stored on s3.
The Pypicloud URL is templated in the Dockerfile in order to be accessed during the container build phase and set by Jenkins.
For the python projects deployment we have one repository per project, those repositories contain:
- Dockerfile
- Python source code
- Kubernetes configuration
- Tests code
- Jenkins configuration
This pipeline doesn’t require a Pypicloud user, because the Ingress configuration of the server will simply reject access from outside the Kubernetes cluster.
TL;DR
We needed a remote package service in python and we looked at 3 solutions:
In the JobTeaser context:
- Infrastructure Kubernetes on AWS
- Internal use only
- Backup of package outside server
- User management at the service level
The winner was Pypicloud.